






芯片资讯
你的位置:TOREX(特瑞仕)线性稳压器(LDO)电源芯片全系列-亿配芯城 > 芯片资讯 > 8x7B MoE与Flash Attention 2结合,不到10行代码实现快速推理
8x7B MoE与Flash Attention 2结合,不到10行代码实现快速推理
- 发布日期:2024-01-05 13:05 点击次数:114 前段时间,Mistral AI 公布的 Mixtral 8x7B 模型爆火整个开源社区,其架构与 GPT-4 非常相似,很多人将其形容为 GPT-4 的「缩小版」。
我们都知道,OpenAI 团队一直对 GPT-4 的参数量和训练细节守口如瓶。Mistral 8x7B 的放出,无疑给广大开发者提供了一种「非常接近 GPT-4」的开源选项。
在基准测试中,Mistral 8x7B 的表现优于 Llama 2 70B,在大多数标准基准测试上与 GPT-3.5 不相上下,甚至略胜一筹。
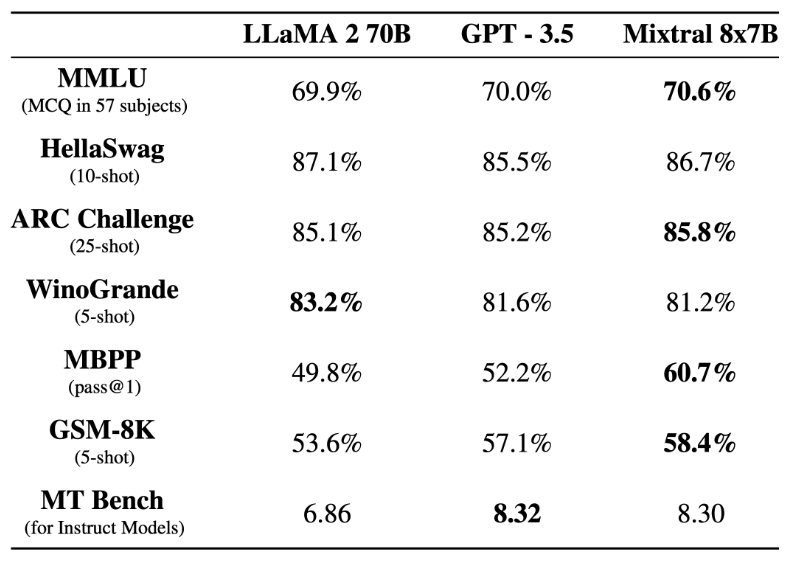
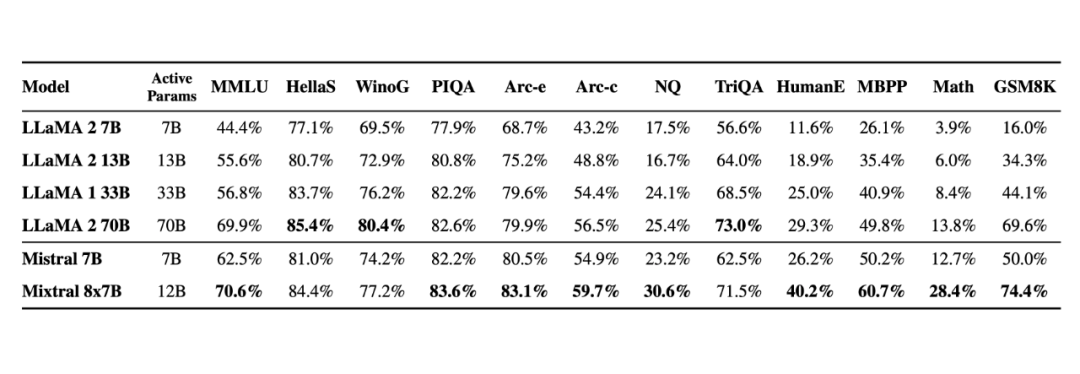 ▲图源 https://mistral.ai/news/mixtral-of-experts/
▲图源 https://mistral.ai/news/mixtral-of-experts/随着这项研究的出现,很多人表示:「闭源大模型已经走到了结局。」
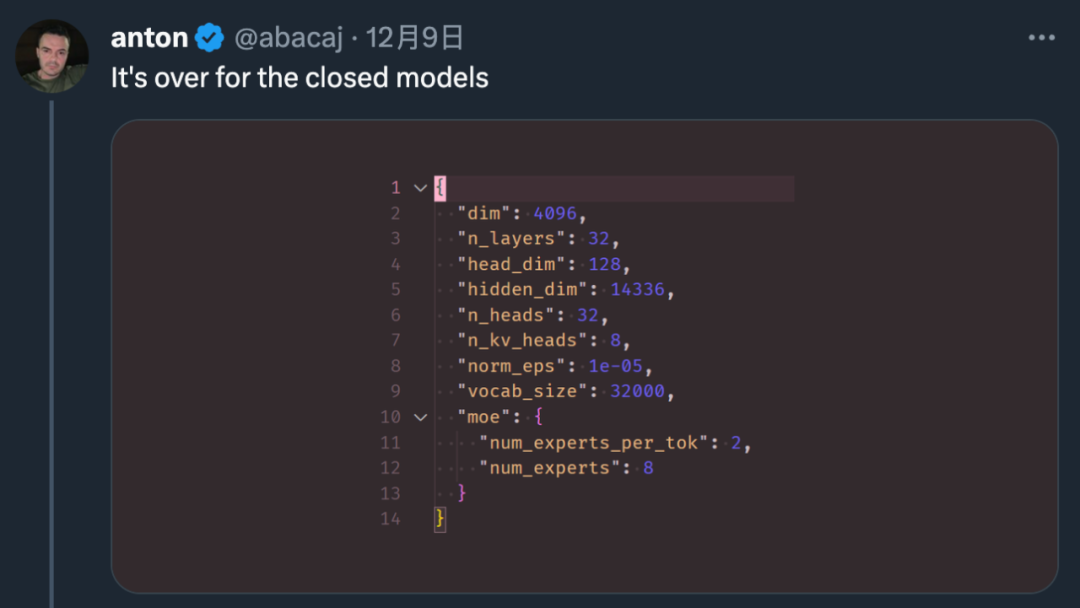
短短几周的时间,TOREX(特瑞仕)线性稳压器(LDO)电源芯片 机器学习爱好者 Vaibhav (VB) Srivastav 表示:随着 AutoAWQ(支持 Mixtral、LLaVa 等模型的量化)最新版本的发布,现在用户可以将 Mixtral 8x7B Instruct 与 Flash Attention 2 结合使用,达到快速推理的目的,实现这一功能大约只需 24GB GPU VRAM、不到十行代码。
 ▲图源 https://twitter.com/reach_vb/status/1741175347821883502
▲图源 https://twitter.com/reach_vb/status/1741175347821883502
AutoAWQ地址:
https://github.com/casper-hansen/AutoAWQ 操作过程是这样的: 首先是安装 AutoAWQ 以及 transformers:
复制pipinstallautoawqgit+https://github.com/huggingface/transformers.git第二步是初始化 tokenizer 和模型:
 第三步是初始化 TextStreamer:
第三步是初始化 TextStreamer:
 第四步对输入进行 Token 化:
第四步对输入进行 Token 化:
 第五步生成:
第五步生成:
 当你配置好项目后,就可以与 Mixtral 进行对话,例如对于用户要求「如何做出最好的美式咖啡?通过简单的步骤完成」,Mixtral 会按照 1、2、3 等步骤进行回答。
当你配置好项目后,就可以与 Mixtral 进行对话,例如对于用户要求「如何做出最好的美式咖啡?通过简单的步骤完成」,Mixtral 会按照 1、2、3 等步骤进行回答。
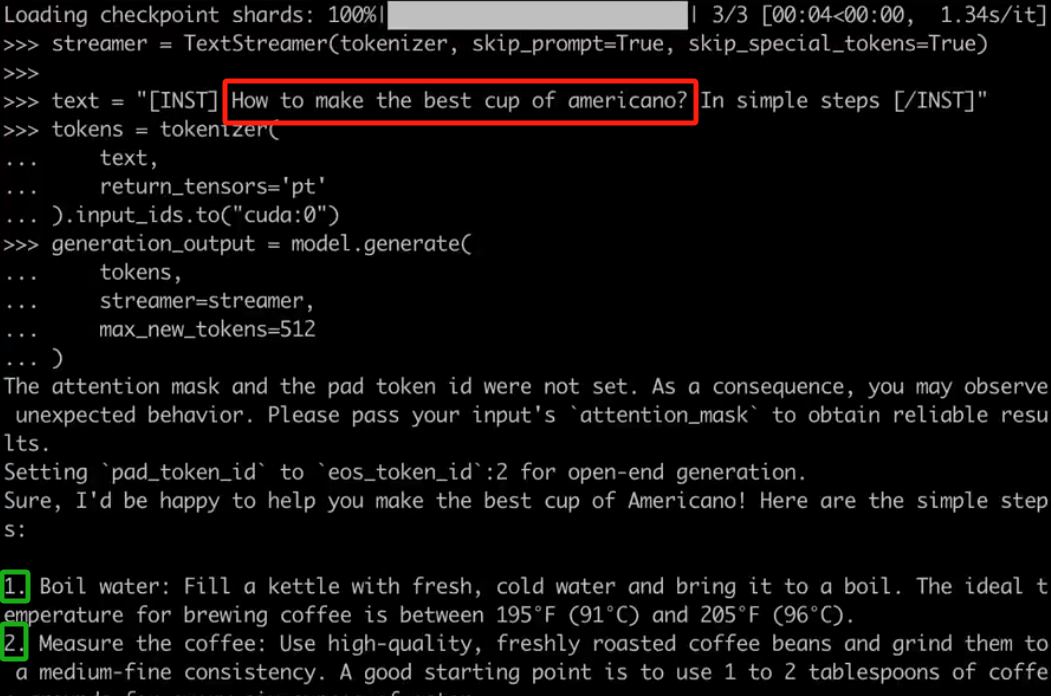
项目中使用的代码:
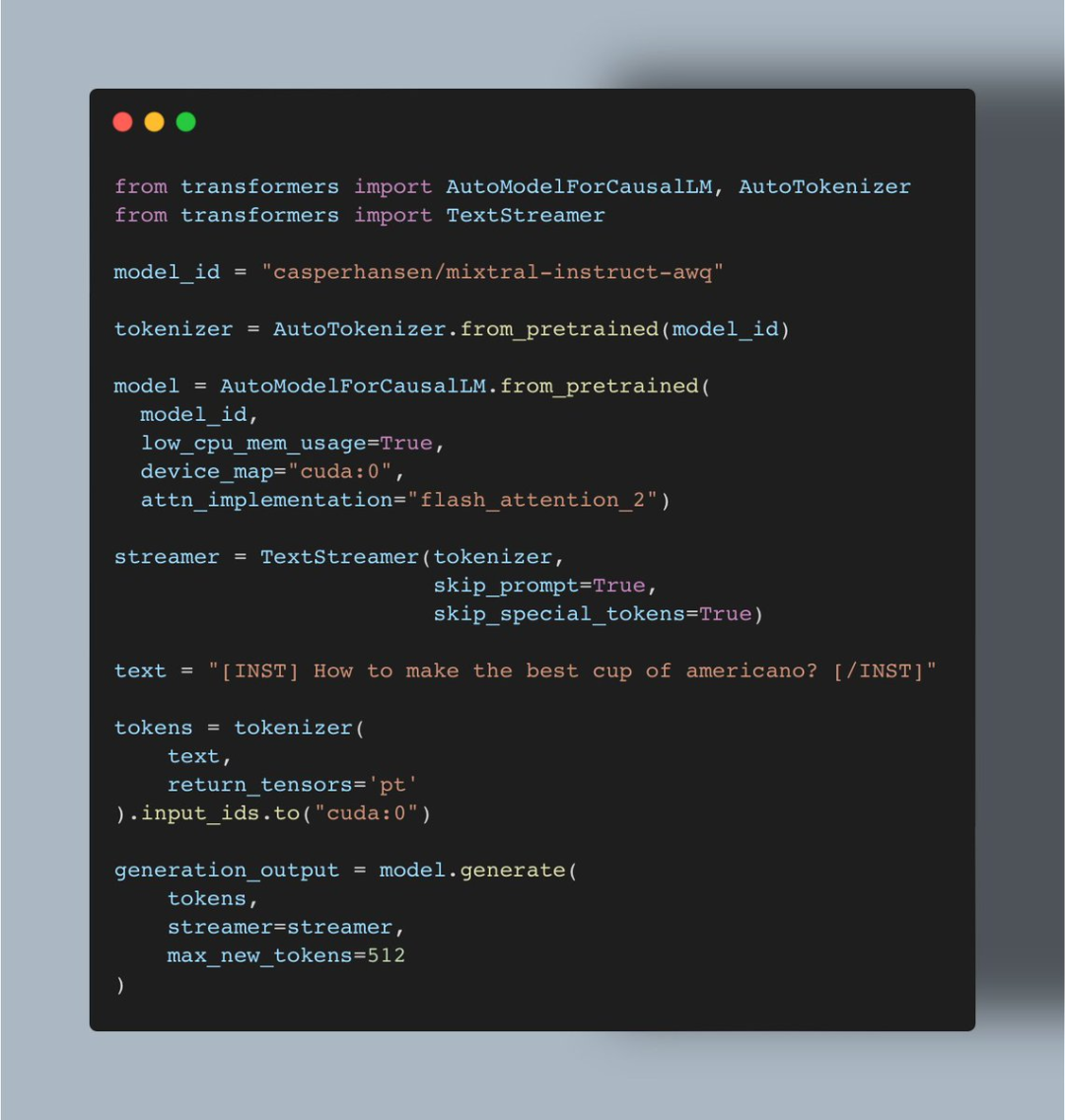
Srivastav 表示上述实现也意味着用户可以使用 AWQ 运行所有的 Mixtral 微调,并使用 Flash Attention 2 来提升它们。 看到这项研究后,网友不禁表示:真的很酷。


相关资讯